Mit dem Fortschreiten der Technologie sind wir schon mittendrin in der Ära des «ubiquitous computing».
Beim Visualisieren des persönlichen digitalen Ökosystems wird deutlich, dass zum Teil identische Daten gleichzeitig auf unterschiedlichsten Geräten und Formaten zur Verfügung stehen müssen. Und zwar, damit diese vom Endbenutzer je nach Kontext, also Computer, Laptop, Tablet, Smartphone oder Smartwatch optimal konsumiert werden können. In einem klassischen CMS Ansatz sind Daten und Format miteinander gekoppelt. Es wird also alles in einem Container zusammengebracht.
Bei der Headless Architektur findet eine Entkopplung von Frontend und Backend statt. Es gibt also einen Container mit allen Daten. Dann können Daten je nach Bedarf, aus diesem Container genommen und in verschiedenen Formaten und Geräten zur Verfügung gestellt werden. Daten je nach Bedarf, aus diesem Container genommen und in verschiedenen Formaten und Geräten zur Verfügung gestellt werden.
Mit dem Einsatz von Headless WordPress für den Datenbestand haben wir den Grundstein gelegt, mehrere Lösungen aus einer Hand anbieten zu können. Zum einen haben wir unseren Container mit dem Datenbestand. Zusätzlich ermöglicht das von uns angepasste WordPress-Dashboard, Daten hinzuzufügen, zu ändern und zu löschen. Ausserdem können durch den Headless Ansatz Daten in verschieden Formaten und auf unterschiedlichsten Geräten, je nach Kontext, optimal bereitgestellt werden. Dies erlaubt uns eine flexible und kosteneffiziente Skalierung.
Was ist mit Kontext gemeint?
Zum einen haben wir natürlich die verschiedenen Geräte wie Computer, Laptop, Tablet oder Smartphones, die einen Kontext entstehen lassen. Beispiel: Auf dem Smartphone können Texte problemlos gelesen werden, die Erstellung dieser Texte ist aber auf einem Laptop oder Computer deutlich angenehmer.
Wissen entsteht durch die Bündelung von Informationen. Informationen entstehen durch die Bündelung von Daten. Identisches Wissen und Informationen respektive Daten werden von verschiedenen Benutzern auf unterschiedliche Art und Weise benutzt. Wichtig ist hierbei natürlich das Ziel der Verwendung. «Erfahren Sie in welchen Projekten, Disziplinen und Partnerschaften eine Institution aktiv ist.», – ein Forscher allerdings, kann aus der gleichen Datenmenge, aus Bündelung und Interpretation dieser, auf ganz andere Informationen, Wissen und Schlüsse folgen, weil seine Sichtweise sich in Form von Ziel und Kontext unterscheidet. Durch die Entkopplung von Frontend und Backend können wir aus dem gleichen Datenbestand unterschiedliche Applikationen entwickeln, um den jeweiligen Kontext und dessen Ziel zu unterstützen.
Wie werden Daten bei einem Headless CMS bereitgestellt?
Grundsätzlich werden APIs und Microservices entwickelt, um die Daten für das Frontend oder die Weiterverwendung bereitzustellen. Es wird genau analysiert, welche Daten wo benötigt werden, denn umso schlanker die API, desto performanter der Datenaustausch.
Wie funktioniert das Frontend mit einem Headless CMS?
Die Formatierung und Darstellung der Daten ist unabhängig von dem CMS. Das CMS dient als Repository für den Datenbestand und ist im Vergleich zu einem klassischen CMS nicht direkt für die Darstellung im Frontend zuständig. Somit ist es möglich und angewandte Praxis, mehrere Frontends mit dem gleichen Datenbestand, je nach Gerät und Kontext, zu entwickeln und bereitzustellen.
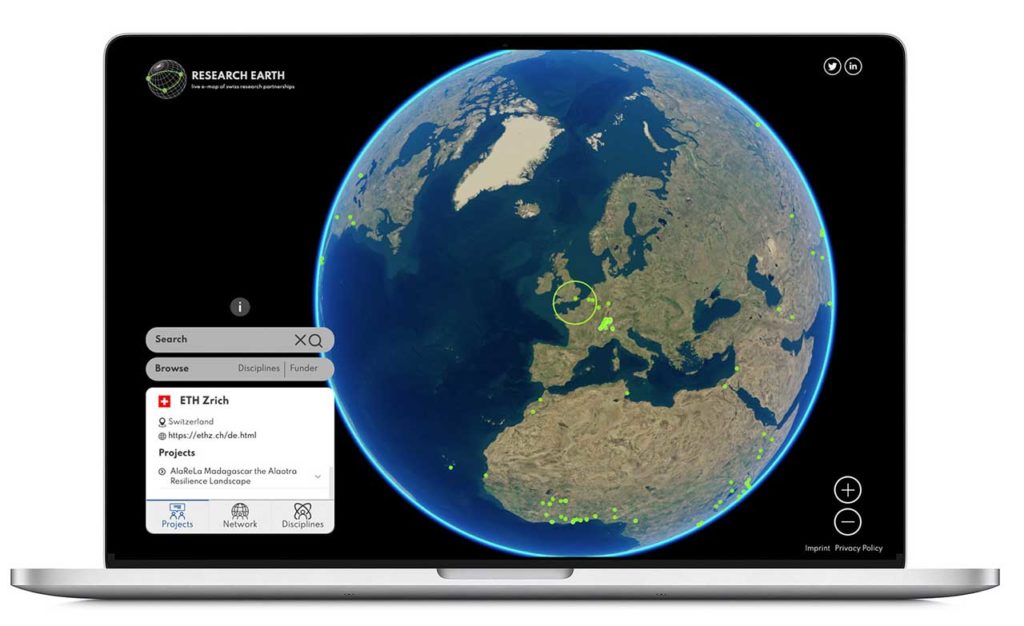
In der ersten Phase des Research Earth Projektes ging es darum alle Institutionen als Marker auf der Weltkarte, mit ihren genauen Adressangaben respektive Koordinaten darzustellen. Wird mit einem Marker, also einer Institution interagiert, werden zusätzliche Informationen, welche in Relation mit dieser Institution angezeigt.
In Co-Creation mit dem Kunden wurden Daten, welche im Frontend dargestellt werden sollten, definiert und das Design Team erstellte das Mockup. Diese Arbeiten definierten die zu entwickelnden APIs. Das Frontend wurde dann mit Cesium und React entwickelt, es ist responsiv, funktioniert also auf allen gängigen Devices.

